Review (Week 6)
LINKED LIST
Single Linked List
Single Linked List merupakan Linked List yang hanya terhubung ke data berikutnya.
Codingan dasar dalam membuat Linked List:
struct node {
int nilaiData;
struct node *next;
};
struct node *head = NULL;
struct node *tail = NULL;
Circular Single Linked List
Circular Single Linked List memiliki bentuk yang sedikit berbeda dengan Single Linked List. Tail->next pada Single Linked List menunjukkan nilai NULL, sedangkan pada Circular Single Linked List, tail->next menunjuk pada head. Sehingga tidak terdapat NULL dalam Circular Single Linked List. Dalam codingan, hanya perlu sedikit modifikasi, yaitu dengan mengubah pointer next pada nilai terakhir menunjuk nilai dari head. Hal ini berlaku untuk insertion dan deletion.
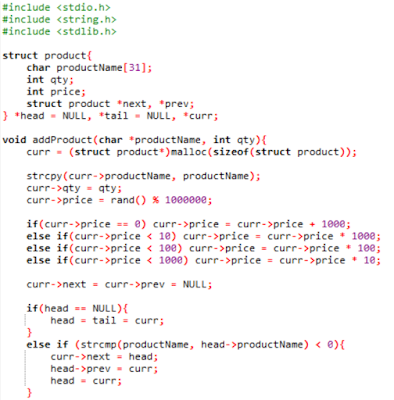
Double Linked List
Double Linked List merupakan Linked List yang terhubung dengan data berikutnya dan data sebelumnya.
struct node {
int nilaiData;
struct node *next;
struct node *prev;
};
struct node *head = NULL;
struct node *tail = NULL;
Insertion
Push depan:
1. Membuat node baru (contoh *curr)
2. Mengisi datanya
3. curr->next diisi nilai head dan curr->prev diisi NULL
4. head->prev menjadi curr
5. head menunjuk ke curr
Untuk push belakang, lakukan modifikasi pada node tail.
Untuk push tengah (contoh diantara node x dan node y):
1. Membuat node baru (contoh *curr)
2. Mengisi datanya
3. curr->next menjadi x->next
4. x->next menjadi curr
5. curr->prev menjadi x
6. Ubah prev dari y menjadi curr
Deletion
Terdapat 4 kondisi:
1. Menghapus satu-satunya node dalam Linked List
-> Melepas memori head dan tail
2. Menghapus head dari Linked List
-> Memindahkan head ke data berikutnya, lalu lepas memori head->prev dan beri nilai NULL pada head->prev
3. Menghapus tail dari Linked List
-> Memindahkan tail ke data sebelumnya, lepas memori tail->next, dan beri nilai NULL pada tail->next
4. Menghapus node yang berada di tengah Linked List
-> Cari nilai yang ingin dihapus dengan mengecek nilai next dari node, apabila sudah ditemukan, buat pointer temporary untuk menyimpan nilai dari node yang akan dihapus, dan nilai yang akan ditampung. Contoh a sebagai nilai pertama, del sebagai nilai yang akan dihapus, dan b sebagai nilai kedua. A->next berisi b, dan b->prev berisi a, kemudian lepas memori del.
Circular Double Linked List
Circular Double Linked List berbentuk sirkuit dimana tidak terdapat nilai NULL pada head->prev maupun tail->next. Head->prev berisi nilai tail dan tail->next berisi nilai head.
Untuk mencetak linked list bisa kita gunakan dengan cara manual, namun cara tersebut tidaklah efektif. Maka dari itu, kita memanfaatkan looping untuk mencetak list-listnya. Pertama, kita pindahkan dulu curr ke head. Kemudian, kita cek apakah nilainya NULL, jika bukan kita print. Setelah itu, kita pindahkan curr ke list setelahnya, kemudian kita cek lagi kondisinya, dan dilakukan berulang kali hingga curr berada pada posisi NULL.
STACK AND QUEUE
Konsep Stack & Queue
Stack : LIFO (Last In First Out)
Queue : FIFO (First In First Out)
Operasi pada Stack
push(x) : Menambah item di atas stack (Menggunakan push tail)
pop : Menghapus item dari stack paling atas (Menggunakan pop tail)
Infix, Postfix, Prefix
Prefix : Operator sebelum operand
Infix : Operator diantara operand
Postfix : Operator setelah operand
Menghitung Postfix
Scan string dari kiri ke kanan, kemudian:
- Jika yang discan merupakan operand, push ke dalam stack
- Jika yang discan merupakan operator, pop dua kali (simpan nilai yang dipop, contoh A dan B), kemudian push (B operator A).
Menghitung Prefix
Scan string dari kanan ke kiri, kemudian:
- Jika yang discan merupakan operand, push ke dalam stack
- Jika yang discan merupakan operator, pop dua kali (simpan nilai yang dipop, contoh A dan B), kemudian push (B operator A).
Konversi Infix ke Postfix
Scan string dari kiri ke kanan, kemudian:
- Jika operand, tambahkan ke dalam string postfix
- Jika tanda '(', push ke dalam stack
- Jika tanda ')', pop stack sampai menemukan tanda '('. Tambakan setiap element yang sudah dipop ke dalam string postfix, kecuali '('.
- Jika operator, pop selama elemen paling atas dari stack memiliki urutan operasi lebih tinggi atau setara dari karakter yang discan. Tambahkan setiap elemen yang sudah dipop ke dalam string postfix. Push karakter yang discan ke dalam stack.
- Setelah scan semua karakter dalam string, pop semua elemen dalam stack dan tambahkan ke dalam string postfix
Konversi Infix ke Prefix
Scan string dari kanan ke kiri, kemudian:
- Jika operand, tambahkan ke dalam string postfix
- Jika tanda '(', push ke dalam stack
- Jika tanda ')', pop stack sampai menemukan tanda '('. Tambakan setiap element yang sudah dipop ke dalam string postfix, kecuali '('.
- Jika operator, pop selama elemen paling atas dari stack memiliki urutan operasi lebih tinggi atau setara dari karakter yang discan. Tambahkan setiap elemen yang sudah dipop ke dalam string postfix. Push karakter yang discan ke dalam stack.
- Setelah scan semua karakter dalam string, pop semua elemen dalam stack dan tambahkan ke dalam string postfix
Operasi pada Queue
- Push(x): Menambah item di belakang queue (Push tail)
- Pop: Menghapus item di depan queue (Pop head)
DFS (Depth First Search) & BFS (Breadth First Search)
DFS dan BFS merupakan teknik pencarian dalam sebuah tree atau graf.
DFS merupakan pencarian yang diusahakan untuk mendapat tree atau graf terpanjang.
BFS merupakan pencarian yang diusahakan untuk mendapat tree atau graf yang lebih pendek, namun melebar
DFS menggunakan stack, BFS menggunakan queue.
HASH TABLE, HASHING, TREES & BINARY TREES
HASHING AND HASH TABLE
Hashing merupakan teknik mengubah setiap record menjadi angka (hash). Kumpulan dari karakter dalam sebuah record diubah dalam bentuk yang lebih pendek (kata kunci) yang merepresentasikan kumpulan karakter itu sendiri.
Contoh hash table:
Misalkan kita ingin menyimpan nama mahasiswa berupa: Doni, Andi, Budi, Fanny, Yadi. Maka, kita dapat mengubah karakter pertama dari setiap string menjadi angka, contohnya a itu 0, b itu 1, c itu 2, sehingga:



Beberapa cara untuk mengubah string menjadi key:
Mid-square
Mengkuadratkan string/identifier, kemudian mengambil beberapa angka dari hasil kuadrat (dari tengah) untuk dijadikan hash key.
Division
Membagi string/identifier dengan menggunakan operator modulus. Biasanya modulo nya berupa ukuran dari table/array atau menggunakan bilangan prima terdekat diatas banyaknya data.
Folding
Membagi string/identifier menjadi beberapa bagian, kemudian jumlahkan bagian-bagian tersebut untuk mendapatkan hash key.
Digit Extraction
Mengambil bagian dari string/identifier yang diberikan.
Contoh: x = 54321, jika kita mengambil angka ke 2 dan 4, kita akan mendapatkan hash key 24.
Rotating Hash
Biasanya dikombinasikan dengan hash function yang lain (misalnya mid-square atau division). Setelah itu membalikkan urutan angka dari belakang ke depan.
COLLISION
Collision merupakan bentrokan/tabrakan antar hash key, dimana terdapat record yang mempunyai hash key yang sama.
Cara mengatasi collision:
Linear Probing >> Mencari tempat kosong di tempat berikutnya dan letakkan string disana.
Cara ini dapat meningkatkan kompleksitas ketika melakukan pencarian.
Chaining >> Meletakkan string dalam slot yang sama menggunakan linked list.
TREES DAN BINARY TREES
Tree merupakan struktur data non linear yang menjelaskan hubugan antar data.
Tree merupakan kumpulan satu node atau lebih.
Binary Tree merupakan tree yang dimana setiap node memiliki paling banyak dua "child".
Ciri-Ciri Binary Trees
Jumlah maksimum node pada setiap level k adalah 2^k.
Jumlah maksimum node dalam sebuah binary tree yang memiliki tinggi h adalah 2^(h+1) - 1
Contoh: h = 4, jumlah maks = 2^4 - 1 = 15.
Tinggi minimum binary tree yang memiliki n nodes adalah 2 log(n).
Tinggi maksimum binary tree yang memiliki n nodes adalah n-1.
Konsep Expression Tree

Prefix: *+/ab-cde
Postfix: ab+cd-e/*
Infix: (a+b) * ((c-d)/e)
Binary Search Tree merupakan struktur data yang mendukung pencarian dan sorting yang cepat, dan juga memudahkan insertion dan deletion.
Binary Search Tree disebut juga Binary Tree yang sudah disorting.
Dalam sebuah node pada Binary Search Tree:
- Subtree kiri terdiri atas elemen yang lebih kecil
- Subtree kanan terdiri atas elemen yang lebih besar
Operasi dalam Binary Search Tree
- find(x) = menemukan x dalam BST
- insert(x) = memasukkan elemen baru ke dalam BST
- remove(x) = menghapus elemen x dari BST
Operasi: Search
- Mulai pencarian dari root
- Jika root merupakan elemen yang kita cari, maka pencarian selesai
- Jika x lebih kecil root, lakukan pencarian secara rekursif ke bagian kiri sub tree BST, begitu pula jika lebih besar, lakukan pencarian secara rekursif ke bagian kanan sub tree BST. Itu berlaku untuk pencarian ke node berikutnya.
Operasi: Insertion
- Mulai dari root
- Jika x lebih kecil node's key, kemudian masukkan x ke sub tree kiri, jika lebih besar, masukkan x ke sub tree kanan
- Ulangi sampai kita menemukan node kosong untuk diisi
Operasi: Deletion
Terdapat 3 kondisi:
- Jika key merupakan leaf, hapus saja nodenya
- Jika key terdapat dalam node yang mempunyai satu "child", hapus node tersebut dan hubungkan "child"nya dengan "parent"nya
- Jika kunci terdapat dalam node yang mempunyai dua "child", temukan "child" paling kanan dari sub tree kirinya (contoh node x), ubah key yang mau dihapus menjadi key node x, kemudian hilangkan x secara rekursif
BINARY SEARCH TREE
Binary Search Tree disebut juga Binary Tree yang sudah disorting.
Dalam sebuah node pada Binary Search Tree:
- Subtree kiri terdiri atas elemen yang lebih kecil
- Subtree kanan terdiri atas elemen yang lebih besar
Operasi dalam Binary Search Tree
- find(x) = menemukan x dalam BST
- insert(x) = memasukkan elemen baru ke dalam BST
- remove(x) = menghapus elemen x dari BST
Operasi: Search
- Mulai pencarian dari root
- Jika root merupakan elemen yang kita cari, maka pencarian selesai
- Jika x lebih kecil root, lakukan pencarian secara rekursif ke bagian kiri sub tree BST, begitu pula jika lebih besar, lakukan pencarian secara rekursif ke bagian kanan sub tree BST. Itu berlaku untuk pencarian ke node berikutnya.
Operasi: Insertion
- Mulai dari root
- Jika x lebih kecil node's key, kemudian masukkan x ke sub tree kiri, jika lebih besar, masukkan x ke sub tree kanan
- Ulangi sampai kita menemukan node kosong untuk diisi
Operasi: Deletion
Terdapat 3 kondisi:
- Jika key merupakan leaf, hapus saja nodenya
- Jika key terdapat dalam node yang mempunyai satu "child", hapus node tersebut dan hubungkan "child"nya dengan "parent"nya
- Jika kunci terdapat dalam node yang mempunyai dua "child", temukan "child" paling kanan dari sub tree kirinya (contoh node x), ubah key yang mau dihapus menjadi key node x, kemudian hilangkan x secara rekursif


Komentar
Posting Komentar